dbt
Transform your data in warehouse
dbt (data build tool) is an open source Python package that enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications. dbt allows you to build your data transformation pipeline using SQL queries.
dbt fits nicely into the modern BI stack, coupling with products like Stitch, Fivetran, Redshift, Snowflake, BigQuery, Looker, and Mode. Here’s how the pieces fit together:
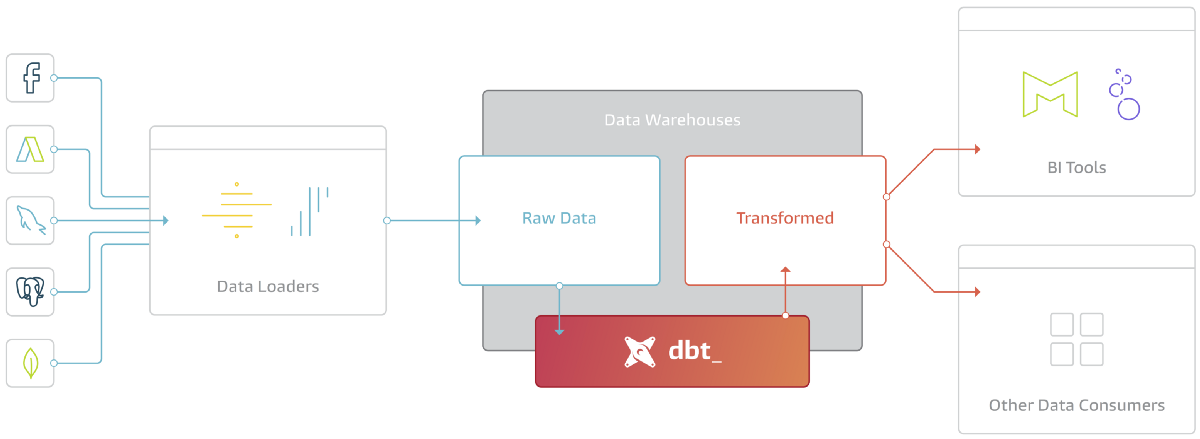
dbt is the T in ELT. It doesn’t extract or load data, but it’s extremely good at transforming data that’s already loaded into your warehouse. This “transform after load” architecture is becoming known as ELT (extract, load, transform).
ELT has become commonplace because of the power of modern analytic databases. Data warehouses like Redshift, Snowflake, and BigQuery are extremely performant and very scalable such that at this point most data transformation use cases can be much more effectively handled in-database rather than in some external processing layer. Add to this the separation of compute and storage and there are decreasingly few reasons to want to execute your data transformation jobs elsewhere.
dbt is a tool to help you write and execute the data transformation jobs that run inside your warehouse. dbt’s only function is to take code, compile it to SQL, and then run against your database.
Key Concepts
- dbt CLI --- CLI stands for Command Line Interface. When you have installed dbt you have available in your terminal the
dbtcommand. Thanks to this you can run a lot of different commands. - a dbt project --- a dbt project is a folder that contains all the dbt objects needed to work. You can initialise a project with the CLI command:
dbt init. - YAML --- in the modern data era YAML files are everywhere. In dbt you define a lot of configurations in YAML files. In a dbt project you can define YAML file everywhere. You have to imagine that in the end dbt will concatenate all the files to create a big configuration out of it. In dbt we use the .yml extension.
- profiles.yml --- This file contains the credentials to connect your dbt project to your data warehouse. By default this file is located in your
$HOME/.dbt/folder. I recommend you to create your own profiles file and to specify the--profiles-diroption to the dbt CLI. A connection to a warehouse requires a dbt adapter to be installed. - a model --- a model is a select statement that can be materialised as a table or as a view. The models are most the important dbt object because they are your data assets. All your business logic will be in the model select statements. You should also know that model are defined in .sql files and that the filename is the name of the model by default. You can also add metadata on models (in YAML).
- a source --- a source refers to a table that has been extracted and load---EL---by something outside of dbt. You have to define sources in YAML files.
- Jinja templating --- Jinja is a templating engine that seems to exist forever in Python. A templating engine is a mechanism that takes a template with "stuff" that will be replaced when the template will be rendered by the engine. Contextualised to dbt it means that a SQL query is a template that will be rendered---or compiled---to SQL query ready to be executed against your data warehouse. By default you can recognise a Jinja syntax with the double curly brackets---e.g.
{{ something }}. - a macro --- a macro is a Jinja function that either do something or return SQL or partial SQL code. Macro can be imported from other dbt packages or defined within a dbt project.
- ref / source macros ---
refandsourcemacros are the most important macros you'll use. When writing a model you'll use these macros to define the relationships between models. Thanks to that dbt will be able to create a dependency tree of all the relation between the models. We call this a DAG. Obviously source define a relation to source and ref to another model---it can also be other kind of dbt resources.
Data modeling techniques for more modularity
https://www.getdbt.com/analytics-engineering/modular-data-modeling-technique/

dbt (data build tool) is an open source Python package that enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications. dbt allows you to build your data transformation pipeline using SQL queries.
What Do Airflow and dbt Solve?
Airflow and dbt share the same high-level purpose: to help teams deliver reliable data to the people they work with, using a common interface to collaborate on that work.
But the two tools handle different parts of that workflow:
- Airflow helps orchestrate jobs that extract data, load it into a warehouse, and handle machine-learning processes.
- dbt hones in on a subset of those jobs – enabling team members who use SQL to transform data that has already landed in the warehouse.
With a combination of dbt and Airflow, each member of a data team can focus on what they do best, with clarity across analysts and engineers on who needs to dig in (and where to start) when data pipeline issues come up.
Trainings
Learn the Fundamentals of Analytics Engineering with dbt
Commands

Case Studies
99 Group

Data Transformation with Snowpark Python and dbt
dbt is one of the most popular data transformation tools today. And until now dbt has been entirely a SQL-based transformation tool. But with the announcement of dbt Python models, things have changed. It's now possible to create both SQL and Python based models in dbt! Here's how dbt explains it:
dbt Python ("dbt-py") models will help you solve use cases that can't be solved with SQL. You can perform analyses using tools available in the open source Python ecosystem, including state-of-the-art packages for data science and statistics. Before, you would have needed separate infrastructure and orchestration to run Python transformations in production. By defining your Python transformations in dbt, they're just models in your project, with all the same capabilities around testing, documentation, and lineage. (dbt Python models). Python based dbt models are made possible by Snowflake's new native Python support and Snowpark API for Python. With Snowflake's native Python support and DataFrame API, you no longer need to maintain and pay for separate infrastructure/services to run Python code, it can be run directly within Snowflake's Enterprise grade data platform!
Makefile
init:
dbt init ${PROJECT_NAME}
debug:
dbt debug
run:
# If you are in dbt directory already, you don't need to export the `DBT_PROFILES_DIR` environment variable otherwise you can export it to run dbt from other folders also
export DBT_PROFILES_DIR=path/to/directory
dbt run
# Alternative way is to directly mention the profile path while running the dbt project
dbt run --profiles-dir path/to/directory
test:
# Running dbt test without mentioning any models will test all the models in the dbt project
dbt test
# If you want to test only specific models, you can use this format
dbt test -m model1 [model2]
seed:
dbt seed
venv:
pipenv --python 3.9.7
pipenv install
pipenv shell
pipenv --venv
pipenv --rm
Profiles
profiles.yml
postgres:
outputs:
dev:
type: postgres
threads: 1
host: <host>
port: 5432
user: postgres
pass: <pass>
dbname: postgres
schema: public
prod:
type: postgres
threads: 1
host: <host>
port: 5432
user: postgres
pass: <pass>
dbname: postgres
schema: public
target: dev
databricks:
outputs:
dev:
host: {HOST}
http_path: {HTTP_PATH}
schema: default
threads: 1
token: {TOKEN}
type: databricks
target: dev
Installation
dbt-core
dbt-databricks
dbt-postgres
dbt-snowflake
dbt-bigquery
More Resources
- Transform your data with dbt and Serverless architecture
- How JetBlue is eliminating the data engineering bottlenecks with dbt
- dbt development at Vimeo
- Best practices for data modeling with SQL and dbt
- https://www.getdbt.com/analytics-engineering/start-here
- https://www.getdbt.com/blog/what-exactly-is-dbt/
- Four Reasons that make DBT a great time saver for Data Engineers
- https://courses.getdbt.com/courses/fundamentals
Read these
- What, exactly, is dbt?
- dbt vs Delta Live Tables
- Four Reasons that make DBT a great time saver for Data Engineers
Watch these videos
- https://www.youtube.com/watch?v=8FZZivIfJVo
- https://www.youtube.com/watch?v=efsqqD_Gak0
- https://www.youtube.com/playlist?list=PLy4OcwImJzBLJzLYxpxaPUmCWp8j1esvT
- What Is DBT and Why Is It So Popular - Intro To Data Infrastructure Part 3
- What is dbt Data Build Tool? | What problem does it solve? | Real-world use cases
- What is dbt(Data Build Tool)?
- DBT Tutorial (data built tool)
- This is the playlist if you get into deep-dive : Data Build Tool (dbt)