Lab: Incremental Data Loading in Azure Data Factory
There are different ways in which we can design incremental loading using ADF. Based on the type of data source, we can have different techniques to implement incremental loading. Some of them are listed here:
- Using watermarks---If the data source is a database or relational table-based system
- Using file timestamps---If the source is a filesystem or blob storage
- Using partition data---If the source is partitioned based on time
- Using folder structure---If the source is divided based on time
Using Watermarks
Let's look at how we can implement a watermark design with ADF using Azure SQL as a source. Let's assume we have a simple table named FactTrips that needs to be incrementally loaded into an Azure SQL table. Proceed as follows:
STEP 1 - Select the Azure SQL service from the Azure dashboard and create a new Azure SQL instance if you don't already have one. Create a simple FactTrips table and insert some dummy values into it using the Query editor option.
DROP TABLE IF EXISTS [dbo].[FactTrips];
CREATE TABLE FactTrips (
[TripID] INT,
[CustomerID] INT,
[LastModifiedTime] DATETIME2
);
INSERT INTO [dbo].[FactTrips] VALUES (100, 200, CURRENT_TIMESTAMP);
INSERT INTO [dbo].[FactTrips] VALUES (101, 201, CURRENT_TIMESTAMP);
INSERT INTO [dbo].[FactTrips] VALUES (102, 202, CURRENT_TIMESTAMP);
SELECT * FROM [dbo].[FactTrips];
STEP 2 - Create a watermark table, like this:
-- A simple watermark table with just the table name and the last update value.
DROP TABLE WatermarkTable;
CREATE TABLE WatermarkTable
(
[TableName] VARCHAR(100),
[WatermarkValue] DATETIME,
);
INSERT INTO [dbo].[WatermarkTable] VALUES ('FactTrips', CURRENT_TIMESTAMP);
SELECT * FROM WatermarkTable;
GO
STEP 3 - Create a stored procedure to automatically update the watermark table whenever there is new data. You can either update the Watermark table manually or create a stored procedure and execute it everytime there is an update.
-- manual method
UPDATE [dbo].[WatermarkTable]
SET [WatermarkValue] = CURRENT_TIMESTAMP
WHERE [TableName] = 'FactTrips';
-- stored procedure to update the watermark whenever there is an update to the FactTable
DROP PROCEDURE uspUpdateWatermark
GO
CREATE PROCEDURE [dbo].uspUpdateWatermark @LastModifiedtime DATETIME, @TableName VARCHAR(100)
AS
BEGIN
UPDATE [dbo].[WatermarkTable] SET [WatermarkValue] = @LastModifiedtime WHERE [TableName] = @TableName
END
GO
-- Executing the stored procedure
DECLARE @timestamp AS DATETIME = CURRENT_TIMESTAMP;
EXECUTE uspUpdateWatermark @LastModifiedtime=@timestamp, @TableName='FactTrips';
SELECT * FROM WatermarkTable;
STEP 4 - Now, on the ADF side, we need to create a new pipeline for finding the delta between the old and new watermarks and then initiate an incremental copy. From the Pipeline page in ADF, create two Lookup activities. They can be found at Activities -> General -> Lookup.
STEP 5 - Configure the first one to look up the previous watermark table entry. The Watermark dataset has been configured to point to the Azure WatermarkTable. Configure the next Lookup activity to look at the latest file modified time in the source table, which in our case would be the FactTrips table.
You will have to enter the following query in the Query textbox under the Settings tab:
SELECT MAX(LastModifiedTime) AS NewWatermarkValue FROM FactTrips;
STEP 6 - Finally, add a new Copy activity from Activities -> Move and Transform -> Copy Data and configure it as follows:
SELECT * FROM FactTrips WHERE
LastModifiedTime > '@{activity('PreviousWatermark').output.firstRow.WatermarkValue}'
AND
LastModifiedTime <= '@{activity('NewWatermark').output.firstRow.WatermarkValue}';

STEP 7 - Save (publish) the preceding pipeline and set up a scheduled trigger using the Add Trigger button in the Pipeline screen. Now, every time there are changes to the FactTrips table, it will get copied into our destination table at regular intervals.
Using File timestamps
There's another technique available to incrementally load only the new files from a source to a destination: ADF's Copy Data tool functionality. This tool provides an option to scan the files at the source based on the LastModifiedDate attribute. So, all we need to do is to specify the source and destination folders and select the Incremental load: LastModifiedDate option for the File loading behavior field.
You can launch the Copy Data tool functionality from the ADF main screen, as shown in the following screenshot:

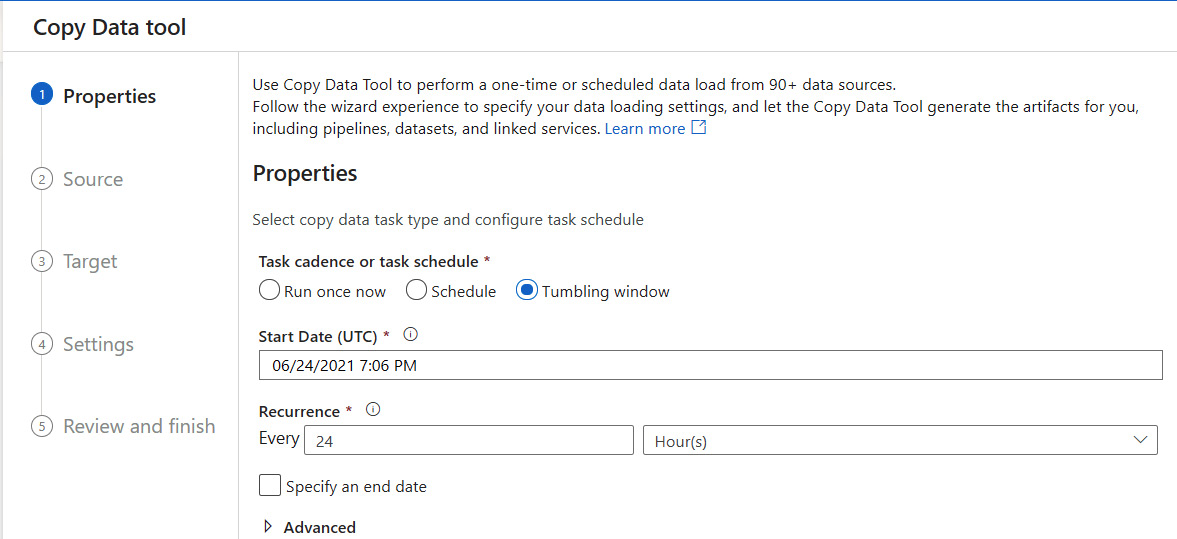
Once you click Copy Data tool, it launches a wizard screen where you can specify the incremental load details, as illustrated in the following screenshot:
NOTE
In the Properties tab shown in the previous screenshot, you need to select Tumbling window for the Task Cadence or task schedule setting; otherwise, the incremental load option won't show up.
In the Source window, select the Incremental load: LastModified Date option, as shown in the following screenshot:
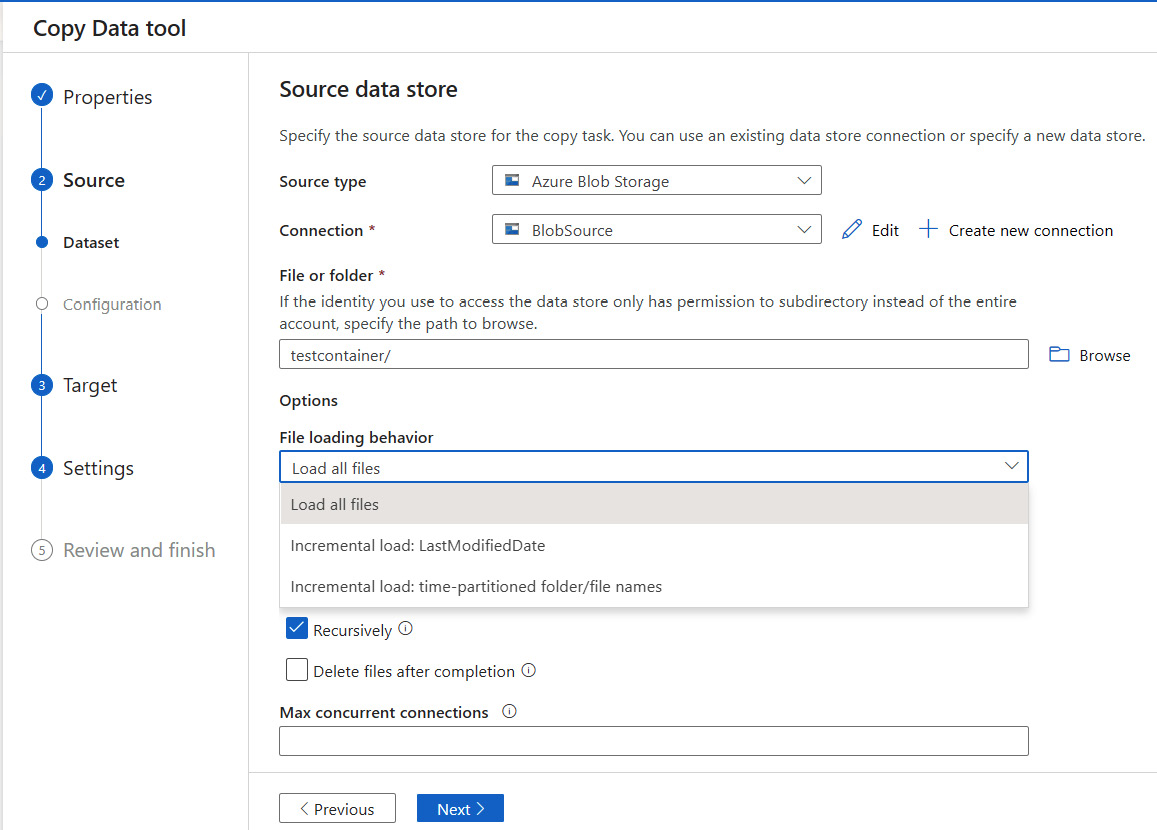
Fill in the rest of the fields and select Next at the Summary screen to create an incremental copy pipeline using file modified dates.
Let's next learn how to do incremental copying using folder structures.
Using File partitions and folder structures
For both the options of file partitioning and data organized in date-based folder structures, we can use the ADF Copy Data tool functionality to perform incremental loading. The files and folders in both approaches will have a similar folder hierarchy based on date/time. Let's assume that our input data is landing in a date-structured folder, as shown here:
New York/Trips/In/2022/01/01
Let's try to incrementally upload this data to another location in the blob storage on a regular basis. ADF's Copy Data tool has support for incremental copying for files and folders that are partitioned using date/time. Similar to how we instantiated a Copy activity in the previous section for the incremental copy based on file modified date timestamps, we need to instantiate the Copy Data tool functionality with the File Loading behavior field set to Incremental load: time-partitioned folder/file names. In this screen, once you start typing the input format using date variables such as {year}/{month}/{day}, the Options section expands to show the year format, month format, and day format fields. You can select your preferred folder structure format using the dropdowns and complete the rest of the flow. The following screenshot shows an example of this:
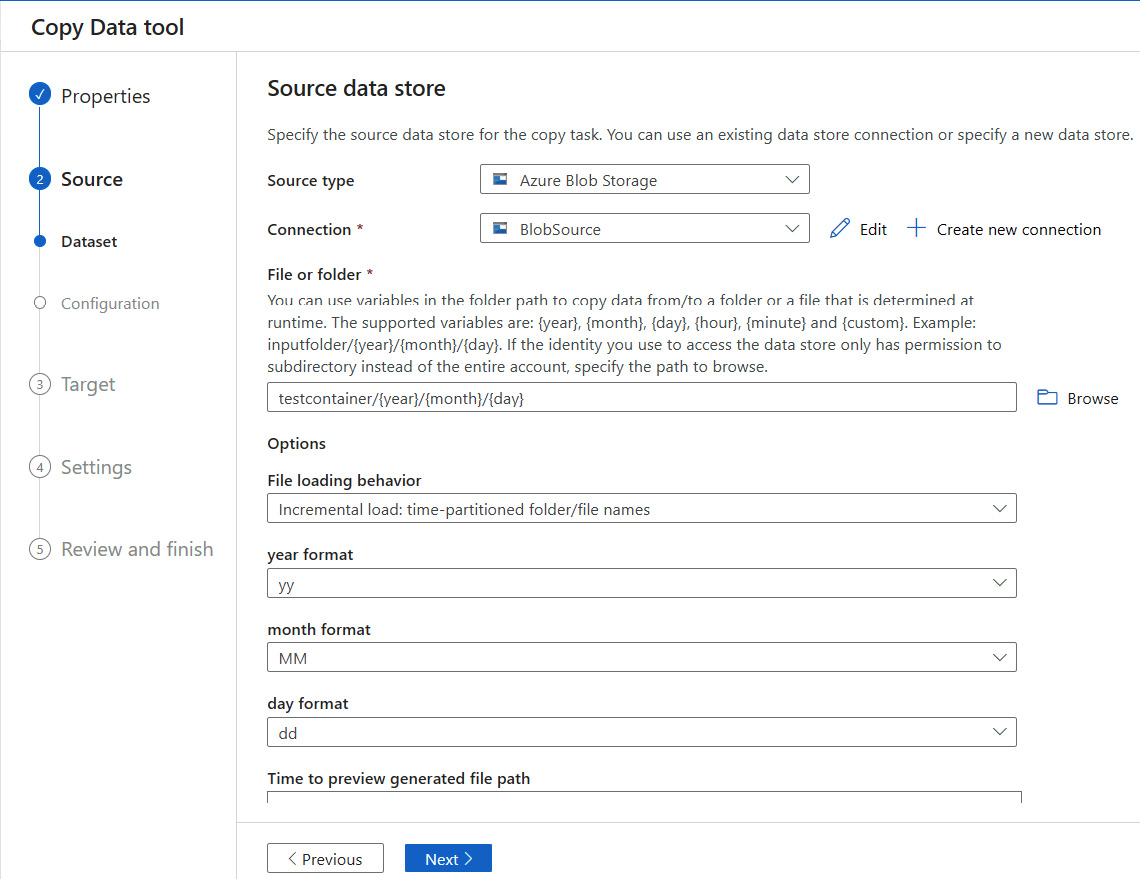
Once you review the details and click Next on the Summary screen, the incremental pipeline for partitioned data/folder structures will get deployed.
We have now learned three different methods to perform incremental copying.